[Python]Python の基本
公開日:2025-12-11
更新日:2025-12-11
更新日:2025-12-11
1. 概要
Python の基本です。
動作確認:Python 3.13.9
動作確認:Python 3.13.9
2. 型
コード
# 数値
v = 1 # int
v = 123.456 # float
# 文字列
v = 'hello' # str
# Bool
v = True # bool
v = False # bool
# NoneType(他の言語の null)
v = None # NoneType
# リスト
v = [1, 2, 3] # <class 'list'>
# タプル(イミュータブル)
v = (1, 2, 3) # <class 'tuple'>
# 集合
v = {1, 2, 3} # <class 'set'>
# 辞書(マップ)
v = {'name': '太郎', 'age': 12} # <class 'dict'>
# バイナリー
v = b"hello" # <class 'bytes'>Python では、値には型がありますが、変数自体には型がないため、他の型の値を代入することができます。
型の表示
コード
print(type(123)) # <class 'int'>3. コメント
コード
# コメント
print('test') # コメントPython にはブロックコメントがありません。
次のように書くと何も実行されないため、ブロックコメントのように扱えますが、裏では文字列が生成されて破棄されたり、__doc__ に代入されたりします。
コード
'''
コメント
コメント
コメント
'''4. 複数行文字列リテラル(ヒアドキュメントのようなもの)
コード
s = '''test
Test
TEST
'''
print(s)実行結果
test
Test
TEST末尾に「\」を付けると行が結合されます。
コード
s = '''test\
Test\
TEST
'''
print(s)実行結果
testTestTEST5. f-string(formatted string literal)
「'」「"」「'''」「"""」の前に f を付けると、「{変数名} 」が値に展開されます。
「{変数名=} 」にすると、「変数名=値」で展開されます。ログ出力に便利。
コード
name = '太郎'
print(f'{name}さん、こんにちは')実行結果
太郎さん、こんにちは「{変数名=} 」にすると、「変数名=値」で展開されます。ログ出力に便利。
コード
name = '太郎'
print(f'{name=}さん、こんにちは')実行結果
name='太郎'さん、こんにちは6. 算術演算
コード
import math
print(20 + 10) # 30
print(20 - 10) # 10
print(20 * 10) # 200
print(20 / 10) # 2.0
print(20 // 3) # 6 商(整数除算)
print(20 % 3) # 2 余り
# 累乗
print(2 ** 3) # 8
# 平方根
print(math.sqrt(2)) # 1.41421356237309517. 文字列操作
コード
# 文字列結合
print('abc' + 'def') # abcdef
# 文字列の長さ(バイト数ではなく文字数)
print(len('test')) # 4
print(len('こんにちは')) # 5
# 部分文字列取得
print('abcdefg'[3:]) # defg インデックス3からから最後まで
print('abcdefg'[:4]) # abcd 先頭からインデックス4まで
print('abcdefg'[2:6]) # cdef インデックス2から6まで
print('abcdefg'[:]) # abcdefg 先頭から最後まで
# 部分文字列取得(負のインデックス)
# マイナスを指定した場合は、インデックスを末尾から先頭に向けて数えるだけで、
# [開始:終了] の形式は同じ。
print('abcdefg'[-4:]) # defg 末尾から4文字目のインデックス~最後
print('abcdefg'[:-4]) # abc 先頭~末尾から4文字目のインデックス
# 大文字・小文字変換
print('hello'.upper()) # HELLO
print('WORLD'.lower()) # world
# 文字列の繰り返し(リピート)
print('0' * 5) # 00000
print('abc' * 3) # abcabcabc
# 頭0埋め
print('1'.zfill(5)) # 00001
print('123'.zfill(5)) # 00123
# 文字列の整列
print('|' + '123'.ljust(7) + '|') # |123 | 左揃え
print('|' + '123'.rjust(7) + '|') # | 123| 右揃え
print('|' + '123'.center(7) + '|') # | 123 | 中央揃え
# トリム(空白の削除)
print('|' + ' Test '.strip() + '|') # |Test| 先頭と末尾の空白削除
print('|' + ' Test '.lstrip() + '|') # |Test | 先頭の空白削除
print('|' + ' Test '.rstrip() + '|') # | Test| 末尾の空白削除
# 改行コード
print('123\n456') # 123
# 456
print("123\n456") # 123
# 456
# 改行のエスケープ
print('123\\n456') # 123\n456
print("123\\n456") # 123\n456
print(r'123\n456') # 123\n456
# 文字列検索(大文字・小文字の区別あり)
print('abcdefg'.find('cd')) # 2
print('abcdefg'.index('cd')) # 2
# 文字列検索(大文字・小文字の区別なし)
print('abcdefg'.lower().find('CD'.lower())) # 2
# 文字列検索で文字列が見つからない場合の挙動
print('abcdefg'.find('x')) # -1
# print('abcdefg'.index('x')) # ValueError が発生する
# 文字列の出現回数のカウント
print('abc ABC abc'.count('abc')) # 2
# 文字列の有無のチェック
print('cd' in 'abcdefg') # True
print('xyz' in 'abcdefg') # False
# 先頭の文字列チェック
print('[test]'.startswith('[')) # True
print('[test]'.startswith('@')) # False
# 末尾の文字列チェック
print('[test]'.endswith(']')) # True
# 置換
print('test test'.replace('t', 'T')) # TesT TesT
# 文字列の分割
print('This is a pen.'.split()) # ['This', 'is', 'a', 'pen.']
print('2025-12-31'.split('-')) # ['2025', '12', '31']
# 配列を結合して文字列にする
print('-'.join(['2025', '12', '31'])) # 2025-12-31
# UTF-8 のバイナリーに変換
print("あいうえお".encode('utf-8')) # b'\xe3\x81\x82\xe3\x81\x84\xe3\x81\x86\xe3\x81\x88\xe3\x81\x8a'
# バイナリーを UTF-8 の文字列に変換
print(b'\xe3\x81\x82\xe3\x81\x84\xe3\x81\x86\xe3\x81\x88\xe3\x81\x8a'.decode('utf-8')) # あいうえお8. 値の比較
コード
print(1 == 1) # True
print(1 == '1') # False
print(5 >= 1) # True
print(5 != 1) # True
print(1.0 == 1) # True
print('abc' == 'abc') # True
print('abc' < 'xyz') # True
print('abc' < 'abcd') # True
print(1 == True) # True
print(0 == False) # True
print(None == 0) # False
print(None == False) # False
print(None == True) # False
print("abc" is None) # False
print("abc" == None) # False : 非推奨
list1 = [1, 2, 3]
list2 = [1, 2, 3]
print(list1 == list2) # True : 値の比較
print(list1 is list2) # False : オブジェクトの比較Python は自動的に型変換を行わないため、=== はありません。
【重要】
「==」は値の比較ですが、クラスで __eq__ をオーバーライドして値を比較するようにしていない場合は、同一オブジェクトかどうかの比較になるため要注意。
9. 型の比較
コード
print(type(1) is int) # True
print(type(1.0) is int) # False
print(type(1.1) is int) # False
print(type(1.1) is float) # True
print(type("abc") is str) # True
print(type(True) is bool) # True
print(type((1,2,3)) is tuple) # True
print(type({'name': '太郎', 'age': 12}) is dict) # True
print(isinstance([1, 2, 3], list)) # True : サブクラスの場合も True
print(type([1, 2, 3]) is list) # True : 完全に同じクラスの場合のみ True
# list のサブクラスの場合は False になるので要注意
print(isinstance(True, int)) # True : bool は int のサブクラスのため True10. 型の変換
コード
# 文字列を数値に変換
print(1 + int('2')) # 3
print(1 + int('002')) # 3
print(1 + int(' 2')) # 3
print(1 + int(' 2 ')) # 3
# print(1 + int('abc2')) # ValueError
print(1 + float('123.4')) # 124.4
print(1 + float('1')) # 2.0
print(bool('True')) # True
# 数値を文字列に変換
print('123' + str(456)) # 123456
print('123' + str(456.0)) # 123456.0
print('123' + str(456.00)) # 123456.0
print('[' + str(True) + ']') # [True]11. 10進数と16進数の変換
コード
# 数値を16進数の文字列に変換
print(hex(65535)) # 0xffff
print(hex(65535 + 1)) # 0x10000
# 16進数の文字列を数値に変換
print(int('0xffff', 16)) # 65535
print(int('0x10000', 16)) # 6553612. 論理演算
or, and, not を使用します。!, &&, || は使えません。
ちなみに、論理演算では [] は False のように扱われますが、[] == False と言う訳ではなありません。
コード
x = 10
print(x == 10 or x == 20) # True : x が10または20の場合にTrue
print(100 >= x and x >= 0) # True : x が0以上100以下の場合にTrue
x = 10
print(not (100 >= x and x >= 0)) # False : 「x が0以上100以下」でない場合にTrue重要
論理演算の結果は、
他の言語では bool になることが多いですが、
Python では、最後に評価した値になります。
例えば次のコードの場合は、[1, 2, 3] が返ります。
[] は bool([]) で False、
次の [] も False、
次の [1, 2, 3] は bool([1, 2, 3]) で True となるため、この時に評価が終了し、[1, 2, 3] が返ります。
制御構文で使う場合は、[1, 2, 3] をまた bool にして判定します。
また、これを利用して、値が空だった場合は、初期値を設定することができます。
and の場合も同様です。
他の言語では bool になることが多いですが、
Python では、最後に評価した値になります。
例えば次のコードの場合は、[1, 2, 3] が返ります。
コード
print([] or [] or [1, 2, 3] or []) # [1, 2, 3][] は bool([]) で False、
次の [] も False、
次の [1, 2, 3] は bool([1, 2, 3]) で True となるため、この時に評価が終了し、[1, 2, 3] が返ります。
制御構文で使う場合は、[1, 2, 3] をまた bool にして判定します。
コード
if [1, 2, 3]:
print("実行される")また、これを利用して、値が空だった場合は、初期値を設定することができます。
コード
s1 = ''
s2 = s1 or 'default' # bool(s1) は False、bool('default') は True のため、'default' が返る
print(s2) # defaultand の場合も同様です。
コード
print([] and [] and [1, 2, 3] and []) # []参考
コード
# True として扱われる
print(bool(123)) # True
print(bool('abc')) # True
print(bool([1, 2, 3])) # True
# False として扱われる
print(bool([])) # False
print(bool('')) # False
print(bool(0)) # False
print(bool(None)) # Falseちなみに、論理演算では [] は False のように扱われますが、[] == False と言う訳ではなありません。
13. 条件分岐 - if
コード
a = 1
b = 2
if a > b:
print('a は b より大きい')
elif a < b:
print('a は b より小さい')
else:
print('a と b は等しい')
# 何も処理しない場合は、pass と書く必要がある
if a > b:
pass
# s が None でない場合に実行
s = 'hello'
if s and print(s):
pass14. ループ - for
コード
for i in range(10): # range(10) は [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
if i == 6:
break
if i % 2 == 0:
continue
print(i) # 1 3 5
else:
print("6 が見つかりませんでした") # break が実行されなかった場合に実行される
for i in range(5):
print(i) # 0 1 2 3 4
for i in range(1, 6):
print(i) # 1 2 3 4 5
# 文字列の文字でループ
for char in "Test":
print(char) # T e s t
# リストの値でループ
for name in ["Taro", "Hanako", "Ichiro"]:
print(name) # Taro Hanako Ichiro
# リストのインデックスと値でループ
for i, name in enumerate(["Taro", "Hanako", "Ichiro"]):
print(f'{i}:{name}') # 0:Taro 1:Hanako 2:Ichiro
# 辞書のキーと値でループ
for key, value in {'name': 'Taro', 'age': 15}.items():
print(f'{key}:{value}') # name:Taro age:1515. ループ - while
コード
i = 0
while i < 5:
print(i) # 0 1 2 3 4
i += 116. リスト
コード
values = [10, 20, 30, 40, 50]
print(values) # [10, 20, 30, 40, 50]
print(values[0]) # 10
print(values[4]) # 50
print(values[-1]) # 50 [-1] は末尾から1番目の要素のインデックス
print(values[-2]) # 40 [-2] は末尾から2番目の要素のインデックス
print(values[1:4]) # [20, 30, 40]
print(values[:]) # [10, 20, 30, 40, 50] 全要素。リストのコピーの作成
# 要素数
print(len(values)) # 5
# 末尾に要素の追加
values.append(60)
print(values) # [10, 20, 30, 40, 50, 60]
# 指定した位置に要素の追加
values.insert(2, 25)
print(values) # [10, 20, 25, 30, 40, 50, 60]
# 指定した位置の要素の削除(スライスで指定可能)
del values[0]
print(values) # [20, 25, 30, 40, 50, 60]
# 末尾の要素の削除
del values[-1] # [20, 25, 30, 40, 50]
print(values)
# 末尾の要素の取得と削除
value = values.pop()
print(values) # [20, 25, 30, 40]
print(value) # 50
# リストを結合して新しいリストの作成(元のリストは影響を受けない)
values2 = values + [100, 100, 100]
print(values2) # [20, 25, 30, 40, 100, 100, 100]
print(values) # [20, 25, 30, 40]
# 指定した値を検索して、最初に見つかった要素を削除。要素が見つからない場合は ValueError
values2.remove(100)
print(values2) # [20, 25, 30, 40, 100, 100]
# リストを繰り返す
print([1, 2, 3] * 3) # [1, 2, 3, 1, 2, 3, 1, 2, 3]
print([0] * 10) # [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] 初期化でよく使う
# 出現数のカウント
print([0, 0, 0, 0, 0, 1, 1, 1].count(1)) # 3
# リストの反転
print(reversed([0, 1, 2, 3])) # <list_reverseiterator object>
print(list(reversed([0, 1, 2, 3]))) # 3, 2, 1, 0
values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(sum(values)) # 55 合計
print(min(values)) # 1 最小値
print(max(values)) # 10 最大値
print(sum(values) / len(values)) # 5.5 平均
# ソート
print(sorted([3, 5, 2, 1, 4])) # [1, 2, 3, 4, 5] 昇順
print(sorted([3, 5, 2, 1, 4], reverse=True)) # [5, 4, 3, 2, 1] 降順
# 全て True なら True
print(all([True, True, True, True])) # True
print(all([True, True, False, True])) # False
print(list(n == 0 for n in [0, 0, 0, 0, 0])) # [True, True, True, True, True] リスト内包表記の結果
print(all(n == 0 for n in [0, 0, 0, 0, 0])) # True : 全て 0 なら True
# 1つでも True なら True
print(any([False, False, True, False])) # True
print(any([False, False, False, False])) # False
print(any(n == 1 for n in [0, 0, 0, 0, 0])) # False : 1つも 1 がないので False
print(any(n == 1 for n in [0, 0, 1, 0, 0])) # True : 1つでも 1 があるので True
# 存在チェック
print(2 in [0, 1, 2, 3, 4]) # True
print(5 in [0, 1, 2, 3, 4]) # False
# 検索
print(['a', 'b', 'c', 'd'].index('d')) # 3
print(['a', 'b', 'c', 'a', 'b', 'c'].index('a', 2)) # 3 : インデックス 2 から検索開始
# 置換
values = [0] * 10
values[2:8] = ['a', 'b'] # [2] ~ [7] を置換([2] ~ [7] を削除して、'a' と 'b' を挿入)
print(values) # [0, 0, 'a', 'b', 0, 0]
values[4:] = [] # 空のリストを代入して、要素の削除も可能
print(values) # [0, 0, 'a', 'b']
# 注意 スライスを使わない場合は、指定したインデックスの要素にリストが代入される
values[1] = []
print(values) # [0, [], 'a', 'b']
# アンパック
values = [4, 5, 6]
print([1, 2, 3, *values, 7, 8, 9]) # [1, 2, 3, 4, 5, 6, 7, 8, 9] # リストの要素を展開します17. 辞書(ディクショナリー、マップ、連想配列)
コード
# 辞書の生成
user = {
'name': 'Taro',
'age': 15,
}
# 取得
print(user['name']) # Taro
# 存在しないキーを指定して取得
# print(user['tel']) # KeyError が発生する
print(user.get('tel', 'default')) # default : キーがない場合は、デフォルト値を返す
# 設定
user['name'] = 'Tarooo'
user['address'] = 'Tokyo' # 追加
print(user) # {'name': 'Tarooo', 'age': 15, 'address': 'Tokyo'}
# 削除
del user['address']
print(user) # {'name': 'Tarooo', 'age': 15}
# アンパック 辞書の内容を展開します
user2 = {**user, 'address': 'Tokyo'}
print(user2) # {'name': 'Tarooo', 'age': 15, 'address': 'Tokyo'}
# コピー
user2 = { **user } # アンパック : user の要素を展開して辞書の再作成
print(user ) # {'name': 'Tarooo', 'age': 15}
print(user2) # {'name': 'Tarooo', 'age': 15}
print(id(user )) # 2334474518336
print(id(user2)) # 2334473972992
# 要素数の取得
print(user) # {'name': 'Tarooo', 'age': 15}
print(len(user)) # 2
# キーの存在チェック
print('name' in user) # True : name が存在する
# キーでループ
for key in user.keys():
print(key) # name age
print(user[key]) # Tarooo 15
# 値でループ
for value in user.values():
print(value) # Tarooo 15
# キーと値でループ
for key, value in user.items():
print(key) # name age
print(value) # Tarooo 15
# 他の辞書で上書き
user = {
'name': 'Taro',
'age': 15,
}
user.update({'age': 16, 'address':'Tokyo'})
print(user) # {'name': 'Taro', 'age': 16, 'address': 'Tokyo'}18. タプル
コード
# タプルの生成
values = (1, 2, 3, 4, 5)
print(values[0]) # 1
print(values[1]) # 2
print(values[2:]) # (3, 4, 5)
# タプルは代入不可
# values[0] = 10 # TypeError
# 多重代入
a, b, c, d, e = values
print(a) # 1
print(b) # 2
# 要素でループ。順序は維持されている
for value in values:
print(value) # 1 2 3 4 5
# タプルを使って、関数で複数の戻り値を返す
def getPoint():
return (10, 20)
x, y = getPoint()
print(x) # 10
print(y) # 20
# タプルの展開
def add(a, b, c):
return a + b + c
values = (1, 2, 3)
print(add(*values)) # 6 : タプルを展開して複数の引数にしてる
# 辞書のキーとしてタプルを使う
values = {}
values[(3, 5)] = "Test"
print(values[(3, 5)]) # test
print(id((3, 5))) # 2461735692352 : ID が変わらない
print(id((3, 5))) # 2461735692352
# 複数の値で比較
version = (5, 3) # メジャーバージョン:5 マイナーバージョン:3
print(version >= (4, 9)) # True
print(version >= (5, 0)) # True
print(version >= (6, 1)) # False19. 集合
コード
# 集合の生成。重複は除去される
ids = {1, 1, 1, 2, 2, 2, 3, 3, 3, 0, 0, 0}
print(ids) # {0, 1, 2, 3}
# インデックスを指定した値の取得は不可
# print(ids[2]) # TypeError
# 要素の追加
ids.add(4)
print(ids) # {0, 1, 2, 3, 4}
# 集合の追加。重複は除去される
ids |= {4, 5, 6, 7}
print(ids) # {0, 1, 2, 3, 4, 5, 6, 7}
# 要素の削除
ids.discard(4)
ids -= {5, 6, 7}
ids.discard(999) # 存在しない値を指定してもエラーにならない
# ids.remove(999) # 存在しない値を指定するとエラーになる
print(ids) # {0, 1, 2, 3}
# 要素のクリア
ids.clear()
print(ids) # set()
# 要素でループ。順序は保証されない
ids = {0, 1, 2, 3}
for id in ids:
print(id) # 0 1 2 3
# 要素数
print(len(ids)) # 4
# 空かどうかの判定
print(not {1, 2, 3}) # False
print(not {}) # True
# 値を取得して削除
print(ids.pop()) # 0 : どの要素が取得されるかは保証されない
print(ids) # {1, 2, 3} pop された値は削除される
# 空になるまで値を取り出してループ
ids = {1, 2, 3, 4, 5}
while (ids):
print(ids.pop()) # 1 2 3 4 5
print(len(ids)) # 0 : 空になる
# 集合の計算
oldIds = {1, 2, 3} # 前回のIDの集合
newIds = { 3, 4, 5} # 今回のIDの集合
print(newIds - oldIds) # {4, 5} : 差集合。今回追加された集合
print(newIds & newIds) # {3, 4, 5} : 積集合。今回と前回で変更がなかった集合
print(oldIds - newIds) # {1, 2} : 差集合。今回削除された集合
print(newIds ^ oldIds) # {1, 2, 4, 5} : 対称差集合(XOR)。今回追加または削除された集合20. 条件演算子(三項演算子)
コード
# True の時の値 if 条件 else False の時の値
a = 5
print(True if a <= 10 else False) # True
a = 15
print(True if a <= 10 else False) # False
# デフォルト値の設定でも使えるが、通常は or を使う
name = 'Taro'
print(name if name else '名無し') # Taro
print(name or '名無し') # Taro
name = ''
print(name if name else '名無し') # 名無し
print(name or '名無し') # 名無し21. 関数
21.1 基本
コード
def add(value1, value2):
return value1 + value2
print(add(1, 2)) # 321.2 引数の省略、引数のデフォルト値
コード
def add(value1 = 0, value2 = 0, value3 = 0):
return value1 + value2 + value3
print(add(1)) # 1
print(add(1, 2)) # 3
print(add(1, 2, 3)) # 621.3 リストをアンパックして複数の引数を渡す
コード
def add(value1, value2, value3):
return value1 + value2 + value3
values = [1, 2, 3]
print(add(*values)) # 621.4 可変長引数
コード
def add(*args):
print(type(args)) # <class 'tuple'> 引数はタプルで受け取れる
result = 0
for value in args:
result += value
return result
print(add(1, 2, 3, 4, 5)) # 1521.5 キーワード引数
引数の名前を指定して、値を渡す
コード
def printUser(name = '', age = '', address = '', tel = ''):
print(f'名前:{name}')
print(f'年齢:{age}')
print(f'住所:{address}')
print(f'電話:{tel}')
printUser(address='Tokyo', name='Taro', age=15)
# 名前:Taro
# 年齢:15
# 住所:Tokyo
# 電話:
# 辞書をアンパックして、引数を渡す
user = {'name':'Hanako', 'address':'Chiba', 'tel':'xxx-xxx', 'age':20}
printUser(**user)
# 名前:Hanako
# 年齢:20
# 住所:Chiba
# 電話:xxx-xxx21.6 キーワード引数を辞書で受け取る
コード
def test(p1: int, p2: int, p3:int, **kwargs):
print(type(kwargs)) # <class 'dict'> 辞書
for key, value in kwargs.items():
print(f'key:{key}, value:{value}')
# key:a, value:10
# key:b, value:20
# key:c, value:30
test(1, 2, 3, a=10, b=20, c=30)21.7 複数の戻り値を返す
コード
def getPoint():
return (10, 20)
x, y = getPoint()
print(x) # 10
print(y) # 2021.8 関数を変数に代入
コード
def add(value1, value2):
return value1 + value2
def sub(value1, value2):
return value1 - value2
def calc(f, value1, value2):
return f(value1, value2)
# 関数を変数に代入
f = add
print(add(1, 2)) # 3
# 関数を引数として渡す
print(calc(add, 1, 2)) # 3
print(calc(sub, 1, 2)) # -121.9 クロージャ
コード
def get_counter():
count = 0
def counter():
nonlocal count # 関数の外側の変数を参照可能にする
count += 1
return count
return counter # 関数を返す
counter1 = get_counter()
counter2 = get_counter()
print(counter1()) # 1
print(counter1()) # 2
print(counter1()) # 3
print(counter2()) # 1 : counter1 と counter2 が参照する count が異なるため、counter2 は 121.10 属性の追加
コード
def test():
print(test.name) # 関数自身は同じ関数名で参照できる
# test() # AttributeError : name が参照できない
test.name = 'Test' # 属性
test() # Test
print(test.name) # Test21.11 型ヒント
引数や戻り値の型のヒントを指定できます。
あくまでもヒントのため、実行時には影響しません。
そのため、int に文字列を設定してもエラーになりません。
あくまでもヒントのため、実行時には影響しません。
そのため、int に文字列を設定してもエラーになりません。
コード
def add(value1: int, value2: int) -> int:
return value1 + value2
print(add(1, 2)) # 3
print(add('a', 'b')) # ab22. クラス
22.1 基本
コード
class User:
# コンストラクタ
def __init__(self, name: str):
# name プロパティの setter で設定する
self.name = name
# プロパティ getter
@property
def name(self) -> str:
return self._name
# プロパティ setter
@name.setter
def name(self, value: str) -> None:
if not value or not value.strip(): # not value は not bool(value) と同じ。空の場合は True になる
raise ValueError('name は必須です')
self._name = value.strip() # 先頭が _ の場合は、慣習的に private の意味。但し、外部から参照可能
# メソッド
def printName(self) -> None:
print(self.name)
user = User('Taro')
print(user.name) # Taro
print(user._name) # Taro : 参照できるが禁止
user.name = 'Hanako'
print(user.name) # Hanako
user.printName() # Hanako22.2 クラス属性
コード
class Test:
value:int = 1
obj1 = Test()
obj2 = Test()
print(Test.value) # 1
print(obj1.value) # 1
print(obj2.value) # 1
Test.value = 123
print(Test.value) # 123
print(obj1.value) # 123
print(obj2.value) # 123
obj1.value = 456 # obj1 にだけ、動的にインスタンス属性が追加される
print(Test.value) # 123
print(obj1.value) # 456 : 動的に追加したインスタンス属性が優先される
print(obj2.value) # 12322.3 staticメソッド
コード
class Test:
@staticmethod
def test():
print('Test')
def test2():
print('Test2')
Test.test()
Test.test2()
obj1 = Test()
obj1.test()
obj2 = Test()
# obj2.test2() # エラー@staticmethod を付けなくても static メソッドとして実行できますが、基本的には付けた方が良いです。
@staticmethod を付けなかった場合、インスタンスから static メソッドを実行した際に、引数に self がないためエラーとなります。
22.4 クラスメソッド
staticメソッドの違いは、引数に呼び出したクラスが渡されてきます。
これにより、オーバーライドされたクラス属性を参照することができます。
これにより、オーバーライドされたクラス属性を参照することができます。
コード
class Test:
NAME: str= 'Test' # クラス属性
@classmethod
def get_name(cls): # 引数にはインスタンスではなくクラスが渡される
return cls.NAME
class TestEx(Test):
NAME = 'TestEx' # クラス属性のオーバーライド
print(Test.get_name()) # Test
print(TestEx.get_name()) # TestEx22.5 クラスの継承
コード
class Test:
def __init__(self, value):
self.value = value
def test(self):
self.subTest()
def subTest(self):
print(f'SubTest:{self.value}')
# Testクラスを継承
class TestEx(Test):
def __init__(self, value):
super().__init__(value) # 親のコンストラクタを呼ぶ
# オーバーライド
def subTest(self):
print(f'SubTestEx:{self.value}')
obj1 = Test(1)
obj1.test() # SubTest:1
obj2 = TestEx(2)
obj2.test() # SubTestEx:2他の言語のプライマリーコンストラクタと間違えやすいので要注意。
22.6 抽象メソッド
コード
from abc import ABC, abstractmethod
class AbstractTest(ABC): # ABC : Abstract Base Class(抽象基底クラス)を継承する
def test(self):
self.subTest()
@abstractmethod
def subTest(self):
pass
class Test(AbstractTest):
# 抽象メソッドの実装。このメソッドを実装しないとエラー
def subTest(self):
print('SubTest')
obj2 = Test()
obj2.test() # SubTest22.7 多重継承
コード
class TestA:
def test(self):
print("A")
class TestB(TestA):
def test(self):
print("B")
super().test() # TestD のインスタンスの場合、TestB の super() は TestC を指す
class TestC(TestA):
def test(self):
print("C")
super().test() # TestD のインスタンスの場合、TestC の super() は TestA を指す
class TestD(TestB, TestC): # TestB と TestC を多重継承。基本的には TestB のメソッドが先に動く
def test(self):
print("D")
super().test() #
objD = TestD()
objD.test() # D B C A
# メソッド解決順序の確認
print(TestD.__mro__) # MRO(Method Resolution Order)
# (<class '__main__.TestD'>, <class '__main__.TestB'>, <class '__main__.TestC'>, <class '__main__.TestA'>, <class 'object'>)
objB = TestB()
objB.test() # B A
objC = TestC()
objC.test() # C A22.8 名前マングリング(Name Mangling)
インスタンス属性の名前の先頭が「__」で始まる場合は、名前が「_クラス名__属性名」に変更されて、外部から参照しづらくなります。
プライベートなインスタンス属性を定義したい場合に使用します。
クラスを継承した場合、子クラスのマングリングされた属性と、親クラスのマングリングされた属性は、異なる属性となるので要注意。
Mangling : 切り刻む
メソッドも同様
プライベートなインスタンス属性を定義したい場合に使用します。
クラスを継承した場合、子クラスのマングリングされた属性と、親クラスのマングリングされた属性は、異なる属性となるので要注意。
Mangling : 切り刻む
コード
class Test:
def __init__(self):
self.__value = 1 # __ で始まる属性は、「_クラス名__属性名」に名前が変更される。
class TestEx(Test):
def __init__(self):
super().__init__()
self.__value = 2 # 裏では _TestEx__value のため、Test の __value とは別物になる
obj1 = TestEx()
# print(obj1.__value) # エラー : __value は参照できないのではなく、存在しない
print(obj1._Test__value) # 1 : 強引に参照できるが、基本的には禁止
print(obj1._TestEx__value) # 2メソッドも同様
コード
class Test:
def __test(self): # __ で始まるため、名前が変更される
print('Test')
def test(self):
self.__test() # クラス内からは参照可能
obj = Test()
obj.test() # Test
obj._Test__test() # Test : 強引に参照できるが、基本的には禁止
# obj.__test() # エラー : __test() は名前が変更されているため、存在しない23. データクラス(dataclass)
クラスに @dataclass を付けると、データを持つクラスを簡単に作成できます。
23.1 基本
通常のクラスの場合
データクラスの場合
また、__init__、__repr__、__eq__、__ne__、__hash__、__order__ が自動生成されます。
__init__ の引数は、型ヒントで指定した全てのフィールドです。
型ヒントにデフォルト値を指定していない場合は、全ての引数を指定する必要があります。
__eq__ と __ne__ がオーバーライドされて、== と != がインスタンス属性の値で比較するようになります。
__repr__ は、わかりやすい形式になります。
「<__main__.OldUser object at 0x000001B1DF5B6E40>」が「User(id=1, name='Taro')」 になる。
コード
class User:
def __init__(self, id: int, name: str):
self.id = id
self.name = name
obj1 = User(1, 'Taro')
print(obj1) # <__main__.OldUser object at 0x000001B1DF5B6E40>
print(obj1.id) # 1
print(obj1.name) # Taro
obj2 = User(1, 'Taro')
print(obj1 == obj2) # False : __eq__ をオーバーライドしていないため、同一オブジェクトかどうかの比較になるデータクラスの場合
コード
from dataclasses import dataclass
@dataclass
class UserData:
id: int
name: str
obj = UserData(1, 'Taro') # 全ての型ヒントが __init__ の引数となる
print(obj) # User(id=1, name='Taro')
print(obj.id) # 1
print(obj.name) # Taro
obj2 = UserData(1, 'Taro')
print(obj == obj2) # True : インスタンス属性の値で比較されるまた、__init__、__repr__、__eq__、__ne__、__hash__、__order__ が自動生成されます。
__init__ の引数は、型ヒントで指定した全てのフィールドです。
型ヒントにデフォルト値を指定していない場合は、全ての引数を指定する必要があります。
__eq__ と __ne__ がオーバーライドされて、== と != がインスタンス属性の値で比較するようになります。
__repr__ は、わかりやすい形式になります。
「<__main__.OldUser object at 0x000001B1DF5B6E40>」が「User(id=1, name='Taro')」 になる。
23.2 __hash__ の違い
__hash__ は、@dataclass(frozen=True) にした場合、インスタンス属性の値がハッシュ値となります。
そのため、異なるオブジェクトでも、インスタンス属性の値が同じであれば、同じハッシュ値となります。
通常のクラスでは、オブジェクトごとにハッシュ値が異なるため、辞書のキーとして使用した場合は、動作が変わります。
そのため、異なるオブジェクトでも、インスタンス属性の値が同じであれば、同じハッシュ値となります。
通常のクラスでは、オブジェクトごとにハッシュ値が異なるため、辞書のキーとして使用した場合は、動作が変わります。
コード
# 通常のクラス
class User:
def __init__(self, name: str):
self.name = name
user1 = User('Taro')
user2 = User('Taro')
data = {}
data[user1] = 1
data[user2] = 2 # 異なるキーのため、上書きされない
print(data[user1]) # 1
print(data[user2]) # 2
# データクラス
from dataclasses import dataclass
@dataclass(frozen=True)
class UserData:
name: str
userData1 = UserData('Taro')
userData2 = UserData('Taro')
data = {}
data[userData1] = 1
data[userData2] = 2 # 同じキーのため、上書きされる
print(data[userData1]) # 2
print(data[userData2]) # 223.3 属性の比較
@dataclass(frozen=True, order=True) のように、order=True をつけると、「<」「<=」「>」「>=」で比較できるようになります。
型ヒントが複数ある場合は、指定した順番で評価されます
型ヒントが複数ある場合は、指定した順番で評価されます
コード
from dataclasses import dataclass
@dataclass(frozen=True, order=True)
class UserData:
id: int
name: str
print(UserData(1, 'aaa') < UserData(1, 'bbb')) # True
print(UserData(1, 'aaa') < UserData(2, 'aaa')) # True
print(UserData(1, 'aaa') < UserData(2, 'bbb')) # True
print(UserData(2, 'aaa') < UserData(1, 'bbb')) # False : 左辺の方が id が大きいため False23.4 インスタンス属性を変更不可にする
@dataclass(frozen=True) にすると、インスタンス生成後、インスタンス属性の変更が不可になります。
変更不可にする実現方法は、__setattr__ と __delattr__ をオーバーライドしてると思われます。
コード
from dataclasses import dataclass
@dataclass(frozen=True)
class UserData:
name: str
user = UserData('Taro')
# user.name = 'Hanako' # エラー
# del user.name # エラー変更不可にする実現方法は、__setattr__ と __delattr__ をオーバーライドしてると思われます。
コード
class User:
def __init__(self, name: str):
self.name = name
# 代入される時に呼ばれる
def __setattr__(self, name, value):
print('set')
# del される時に呼ばれる
def __delattr__(self, name):
print('del')
user = User('Taro')
user.name = 'Hanako'
del user.name24. 定数
24.1 全て大文字の変数を定数とする
慣習的なものなので、変更は可能。
コード
MAX_VALUE = 100
MAX_VALUE = 200
print(MAX_VALUE) # 200 : 変更できてしまうので要注意24.2 読み取り専用のプロパティを定数とする
コード
class AppConst:
@property
def MAX_VALUE(self) -> int:
return 256
appConst = AppConst()
print(appConst.MAX_VALUE) # 256
# appConst.MAX_VALUE = -1 # エラー : setter がないため。25. ビット演算
コード
# OR
a = 0b00000001
b = 0b00000110
c = a | b
print(f'{c:08b}') # 00000111
# AND
a = 0b00001111
b = 0b00001000
c = a & b
print(f'{c:08b}') # 00001000
#XOR
a = 0b00001111
b = 0b11111111
c = a ^ b
print(f'{c:08b}') # 11110000 : 全てのビットを1にして XOR するとビットが反転する
# NOT
a = 0b00000001
c1 = ~a
c2 = ~a & 0b11111111 # 符号なしにするには、必要なビット数で AND する
print(f'{c1:08b}') # -0000010 = -2
print(f'{c2:08b}') # 11111110
# 特定のビットをクリアする
a = 0b11111111
b = 0b00001000 # 4ビット目をクリアする場合
c = a & ~b # 反転させて AND する
print(f'{c:08b}') # 11110111 : 4ビット目がクリアされる
# ビットが立っているか確認
a = 0b00000111
print(bool(a & 0b00000100)) # True : 3ビット目が立っている
print(bool(a & 0b00001000)) # False : 4ビット目は立っていない26. 列挙型
コード
from enum import Enum, StrEnum, Flag, auto
# 値が数値の列挙型
class YesNo(Enum):
YES = 1
NO = 2
result = YesNo.YES
print(result == YesNo.YES) # True
print(result == YesNo.NO) # False
print(YesNo.YES.name) # YES
print(YesNo.YES.value) # 1
print(YesNo.NO.value) # 2
# auto() で自動採番
class Color(Enum):
RED = auto()
GREEN = auto()
BLUE = auto()
print(Color.RED.name) # RED
print(Color.RED.value) # 1
print(Color.GREEN.value) # 2
print(Color.BLUE.value) # 3
# auto() はクラスごとに採番される
class Color2(Enum):
RED = auto()
GREEN = auto()
BLUE = auto()
print(Color2.RED.value) # 1 : Color とは別に採番されている
class Color3(Enum):
NONE = 10
RED = auto()
GREEN = auto()
BLUE = auto()
print(Color3.RED.value) # 11 : auto() の直前の値 + 1
print(Color3.GREEN.value) # 12
print(Color3.BLUE.value) # 13
# 値が文字列の列挙型
class Color4(StrEnum):
NONE = 'NONE'
RED = auto()
GREEN = auto()
BLUE = auto()
print(Color4.RED.value) # red : auto() で小文字の名前が設定される
print(Color4.GREEN.value) # green
# フラグとして使う列挙型。auto() で 2 の累乗が自動採番される
class Permission(Flag):
READ = auto()
WRITE = auto()
DELETE = auto()
EXECUTE = auto()
print(Permission.READ.value) # 1
print(Permission.WRITE.value) # 2
print(Permission.DELETE.value) # 4
print(Permission.EXECUTE.value) # 8
# 2 の累乗で定義されているため、ビット演算が可能
permission = Permission.READ | Permission.WRITE
# フラグの確認
print(f'{permission.value:08b}') # 00000011 : 2 進数で表示
print(Permission.READ in permission) # True
print(Permission.WRITE in permission) # True
print(Permission.DELETE in permission) # False
print(Permission.EXECUTE in permission) # False
# フラグの追加
permission |= Permission.DELETE
print(f'{permission.value:08b}') # 00000111
# フラグの削除
permission &= ~Permission.READ # ~ でフラグを反転させて、削除したいフラグだけが 1 の状態にして AND
print(f'{permission.value:08b}') # 0000011027. ラムダ式
コード
# 基本は1行で書く
# 引数 : 式
add = lambda v1, v2: v1 + v2
print(add(1, 2)) # 3
# 括弧で囲むと改行可能
add = lambda v1, v2: (
v1 + v2
)
print(add(1, 2)) # 3
# バックスラッシュで改行可能
add = lambda v1, v2: \
v1 + v2
print(add(1, 2)) # 3
# 奇数の場合 True
isOdd = lambda v: v % 2 == 1
print(isOdd(1)) # True
print(isOdd(2)) # False28. map
リストの各要素に関数を適用します。
map の戻り値は、使い切り型のイテレータです。
for や list() で使った時に評価されます。
注意:map() は使い切り型のイテレータのため、2回目の for は何も実行されません。
map の戻り値は、使い切り型のイテレータです。
for や list() で使った時に評価されます。
コード
values = [1, 2, 3, 4, 5]
values2 = map(lambda value:value + 5, values)
# list() を実行した時に、map の中のラムダ式が実行される
print(list(values2)) # [6, 7, 8, 9, 10]
print(values) # [1, 2, 3, 4, 5] 元のリストは影響を受けない
# map に関数を渡す場合
def add5(value):
return value + 5
values3 = map(add5, values)
print(list(values3)) # [6, 7, 8, 9, 10]注意:map() は使い切り型のイテレータのため、2回目の for は何も実行されません。
コード
values = [1, 2, 3, 4, 5]
values2 = map(lambda value:value + 5, values)
for value in values2:
print(value) # 6 7 8 9 10
# values2 はイテレータの現在位置が最後まで移動しているため、再度ループしても何も実行されない
# 繰り返し使う場合は、list() でリスト化しておく
for value in values2:
print(value) # 実行されない29. filter
リストの各要素を関数で絞り込みます。
map() と同様に遅延評価です。
map() と同様に遅延評価です。
コード
values = [1, 2, 3, 4, 5]
# 奇数だけ抽象する
values2 = filter(lambda v: v % 2 == 1, values)
print(list(values2)) # [1, 3, 5]
print(values) # [1, 2, 3, 4, 5] 元のリストは影響を受けない30. zip
各リストの同一インデックスの要素をタプルにして取得します。
コード
ids = [1, 2, 3, 4, 5, 6, 7]
names = ['Taro', 'Hanako', 'Jiro', 'Saburo', 'Shiro']
for id, name in zip(ids, names):
print(f'ID:{id}, Name:{name}')
# ID:1, Name:Taro
# ID:2, Name:Hanako
# ID:3, Name:Jiro
# ID:4, Name:Saburo
# ID:5, Name:Shiro
# 6 と 7 は、対応する names の要素がないため出力されない31. リスト内包表記
コード
values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 値を2倍にしたリストを作成する
print([v * 2 for v in values])
# [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
# 奇数の値だけを抽出したリストを作成する
print([v for v in values if v % 2 == 1])
# [1, 3, 5, 7, 9]
# if を複数指定することもできる
print([v for v in values if v % 2 == 1 if v >= 5])
# [5, 7, 9]
# 2重ループ
print([f'{i}-{j}' for i in range(1, 4) for j in range(1, 6)])
# ['1-1', '1-2', '1-3', '1-4', '1-5', '2-1', '2-2', '2-3', '2-4', '2-5', '3-1', '3-2', '3-3', '3-4', '3-5']
# 2重ループ + if
print([f'{i}-{j}' for i in range(1, 9) if i > 5 for j in range(1, 9) if j > 5])
print([f'{i}-{j}' for i in range(1, 9) for j in range(1, 9) if i > 5 if j > 5])
# ['6-6', '6-7', '6-8', '7-6', '7-7', '7-8', '8-6', '8-7', '8-8']
# 同じ結果になるが、前者は i > 5 の時だけ内側のループが実行されるため速い32. ウォルラス演算子(Walrus Operator)
「:=」で代入すると、代入後にその値をそのまま利用することができます。
コード
# 式で代入を行い、その値を利用する
b = (a := 3) + 5 # a に 3 が代入されて、そのあとで a + 5 が計算される
print(a) # 3
print(b) # 8
# if の式で代入を行い、その値を利用する
values = [1, 2, 3, 4, 5]
if (length := len(values)) > 3:
print(length) # 5
# 2倍にした値が 3 より大きい値のリストを作成する
# 比較の時に使った tmp を、そのままリストの要素として使える
print([tmp for v in values if (tmp := v * 2) > 3])
# [4, 6, 8, 10]33. 例外処理
コード
import sys, traceback
try:
result = 5 / 0 # 0 で割っているため、ZeroDivisionError が発生する
except Exception as e:
# 例外が起きた場合に実行される
print(e.__class__.__name__) # ZeroDivisionError : 例外の名前
print(type(e).__name__) # ZeroDivisionError : 例外の名前
print(str(e)) # division by zero : エラーメッセージ
print(repr(e)) # ZeroDivisionError('division by zero')
# トレースバック(スタックトレース)の表示
traceback.print_exc()
print(''.join(traceback.format_tb(e.__traceback__)))
# 例外情報の取得
exc_type, exc_value, exc_traceback = sys.exc_info()
print(exc_type) # <class 'ZeroDivisionError'>
print(exc_value) # division by zero
print(exc_traceback) # <traceback object at 0x0000028AEBA02E40>
print(e.__traceback__) # <traceback object at 0x0000028AEBA02E40>
else:
# 例外が起きなかった場合に実行される
print(result)
finally:
# 必ず実行される
print('finally')34. ダンダー属性、ダンダーメソッド
先頭に「__(ダブルアンダースコア)」が付く属性やメソッドです。
これにより、VS Code などで関数にマウスカーソルを合わせた時などに、__doc__ の内容がヒントとして表示されるようになります。
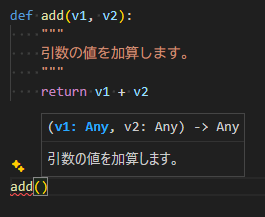
34.1 __init__
コンストラクタのメソッド
コード
class Test:
def __init__(self, value: int):
self.value = value
obj = Test(5)
print(obj.value) # 534.2 __class__
オブジェクトからクラスを参照できます。
コード
class Test:
MAX_VALUE: int = 100 # クラス属性
class TestEx(Test):
MAX_VALUE: int = 1000 # クラス属性のオーバーライド
obj = Test()
print(obj.__class__) # <class '__main__.Test'>
print(obj.__class__.__name__) # Test : クラス名。 ハードコーディングしないで参照できる
print(obj.__class__.MAX_VALUE) # 100 : クラス属性。ハードコーディングしないで参照できる
obj = TestEx()
print(obj.__class__.MAX_VALUE) # 100034.3 __dict__
コード
class Test:
MAX_VALUE: int = 100 # クラス属性
def __init__(self):
self.value1 = 0 # インスタンス属性
self.value2 = 0 # インスタンス属性
def test(self):
pass
obj = Test()
print(obj.__dict__) # {'value1': 0, 'value2': 0}
for key, value in Test.__dict__.items():
print(f'key:{key}, value:{value}')
# key:__module__, value:__main__
# key:__firstlineno__, value:972
# key:__annotations__, value:{'MAX_VALUE': <class 'int'>}
# key:MAX_VALUE, value:100
# key:__init__, value:<function Test.__init__ at 0x0000025824ACFA60>
# key:test, value:<function Test.test at 0x0000025824AE4720>
# key:__static_attributes__, value:('value1', 'value2')
# key:__dict__, value:<attribute '__dict__' of 'Test' objects>
# key:__weakref__, value:<attribute '__weakref__' of 'Test' objects>
# key:__doc__, value:None34.4 __str__ 、__repr__
コード
class Test:
def __init__(self, value):
self.value = value
# print() や str() で呼ばれる
def __str__(self):
return str(self.value)
# repr() で呼ばれる。または __str__ がない場合に、print() や str() で呼ばれる
def __repr__(self):
return f'value:{self.value}' # 開発者に向けた内容
obj = Test(5)
print(obj) # 5 : __str__ が呼ばれる。ない場合は、__repr__ が呼ばれる
print(str(obj)) # 5 : __str__ が呼ばれる。ない場合は、__repr__ が呼ばれる
print(repr(obj)) # value:5 : __repr__ が呼ばれる
# 辞書を print() した場合、__repr__ の有無で表示が変わる
values = [obj, obj, obj]
print(values) # [value:5, value:5, value:5]
#
# __repr__ がない場合は、次のように表示されるため、わかりづらい
# [<__main__.Test object at 0x0000014A90536E40>,
# <__main__.Test object at 0x0000014A90536E40>,
# <__main__.Test object at 0x0000014A90536E40>]34.5 __getitem__
オブジェクトの属性をリストや辞書のように参照できます。
コード
class Test:
def __init__(self, values):
self.values = values
def __getitem__(self, index):
return self.values[index]
obj = Test([1, 2, 3, 4, 5])
print(obj[0]) # 1 : __getitem__ により、リストのように参照できる
print(obj[1]) # 2
print(obj[2:4]) # [3, 4] : __getitem__ の index には slice オブジェクトが渡される
class Test2:
def __init__(self, id, name):
self.id = id
self.name = name
def __getitem__(self, key):
return getattr(self, key) # 指定した名前のインスタンス属性の取得
obj2 = Test2(1, 'Taro')
print(obj2['id']) # 1 : __getitem__ により、辞書のように参照できる
print(obj2['name']) # Taro34.6 __call__
オブジェクトを関数のように呼び出せるようにします。
コード
# 加算
class Add:
def __call__(self, value1, value2):
return value1 + value2
add = Add()
print(add(1, 2)) # 3 : __call__ により、関数のように呼び出せる
# カウンター
class Counter:
def __init__(self):
self.count = 0
def __call__(self):
self.count += 1
return self.count
counter = Counter()
print(counter()) # 1
print(counter()) # 2
print(counter()) # 334.7 __doc__
コード
def add(v1, v2):
"""
引数の値を加算します。
"""
return v1 + v2
f = add(1, 2)
print(add.__doc__) # 「引数の値を加算します。」が表示されるこれにより、VS Code などで関数にマウスカーソルを合わせた時などに、__doc__ の内容がヒントとして表示されるようになります。
35. デコレーター
35.1 既存の関数への上書き
Python は、既存の関数に対して、他の値を上書きすることができます。
コード
def test():
return 123
f = test # f に関数の参照を代入
test = 1 # 既存の関数を上書き
print(test) # 1 : 上書きされたため、関数ではなくなる
print(f()) # 123 : 関数はオブジェクトのため、参照があれば実行可能35.2 デコレーター構文
デコレーター構文を理解するため、あえて不完全なコードにしています。
test() の戻り値(0)は、print_hello に代入されます。
そのため、print(print_hello) は 0 が表示されます。
print_hello は関数ではなくなっているため、print_hello() をするとエラーになります。
コード
def test(func): # @test の次の行の関数が引数で渡されてくる
print(func.__name__) # print_hello : @test の次の行の関数が渡されてきている
return 0 # @test の次の行の関数が、0 になる
@test # デコレーター構文
def print_hello():
print('Hello') # まだ実行されない
print(print_hello) # 0 : print_hello は、test() の戻り値で上書きされているため 0 になる
# print_hello() # エラー : print_hello は関数ではなく、数値に置き換わっている
# 実行結果
# print_hello
# 0test() の戻り値(0)は、print_hello に代入されます。
そのため、print(print_hello) は 0 が表示されます。
print_hello は関数ではなくなっているため、print_hello() をするとエラーになります。
35.3 デコレーター
既存の関数の前後に処理を追加します。
渡された関数は、test() の内部で定義される関数で使われます。この時に、print_hello の前後に処理を追加できる。
そして test() は内部で定義した関数を返し、
それが、@test の次の行の print_hello に代入されます。
ちなみに、wrapper() の前に @wraps(func) を付けなくても動作しますが、
付けない場合は、print_hello の __name__ や __doc__ が wrapper() のものになります。
クラスでも書ける
__call__ は、これはクラスを関数と同じように呼べるようにする仕組みです。
引数は次の行の関数 print_hello です。
そして、__call__ の中で関数 wrapper を定義して返します。
これにより、
@Test(10)
は、
@wrapper
のようになります。
そして、この wrapper が、次の行の関数 print_hello に代入されます。
これにより、print_hello() を実行すると、
元の print_hello() を含んだ wrapper() が実行されるようになります。
コード
from functools import wraps
def test(func):
# 関数の中で関数を定義して返す
@wraps(func)
def wrapper(*args, **kwargs):
print('-----')
result = func(*args, **kwargs) # 元の関数を実行する
print('-----')
return result
return wrapper
@test # デコレーター構文
def print_hello():
""" Hello と表示します """
print('Hello')
print_hello() # -----
# Hello
# -----
print(print_hello.__name__) # print_hello
help(print_hello) # 正常に表示される渡された関数は、test() の内部で定義される関数で使われます。この時に、print_hello の前後に処理を追加できる。
そして test() は内部で定義した関数を返し、
それが、@test の次の行の print_hello に代入されます。
ちなみに、wrapper() の前に @wraps(func) を付けなくても動作しますが、
付けない場合は、print_hello の __name__ や __doc__ が wrapper() のものになります。
クラスでも書ける
コード
from functools import wraps
class Test:
def __init__(self, num):
self.num = num
def __call__(self, func):
@wraps(func)
def wrapper(*args, **kwargs):
print('-' * self.num)
result = func(*args, **kwargs) # 元の関数の実行
print('-' * self.num)
return result
return wrapper
@Test(10) # print_hello に wrapper() が代入される
def print_hello():
""" Hello と表示します """
print('Hello')
return 0
print_hello() # ----------
# Hello
# ----------
print(print_hello.__name__) # print_hello
help(print_hello) # 正常に表示される__call__ は、これはクラスを関数と同じように呼べるようにする仕組みです。
引数は次の行の関数 print_hello です。
そして、__call__ の中で関数 wrapper を定義して返します。
これにより、
@Test(10)
は、
@wrapper
のようになります。
そして、この wrapper が、次の行の関数 print_hello に代入されます。
これにより、print_hello() を実行すると、
元の print_hello() を含んだ wrapper() が実行されるようになります。
36. スクリプトとして実行された時だけ関数を実行する
最初に実行されたモジュールでは、__name__ に、__main__ と言う文字列が設定されます。
インポートされた場合は、__name__ に、モジュール名が設定されます。
そのため、次のように書くと、スクリプトとして実行された時だけ、特定の関数を実行することができます。
インポートされた場合は実行されません。
インポートされた場合は、__name__ に、モジュール名が設定されます。
そのため、次のように書くと、スクリプトとして実行された時だけ、特定の関数を実行することができます。
インポートされた場合は実行されません。
コード
if __name__ == "__main__":
main()
