Python - ディープラーニング - CNN(畳み込みニューラルネットワーク)による図形判別
公開日:2019-11-15
更新日:2019-12-01
更新日:2019-12-01
1. 概要
CNN(畳み込みニューラルネットワーク)により、図形判別を行います。
全結合層(これまでに説明してきたニューラルネットワークの層)では、1つの層を1次元で表していました。
そのため、画像などの2次元のデータを扱うには、データを1次元に変換する必要があり、そこで画像としての特徴が失われる問題点がありました。
そこで CNN では、畳み込み層とプーリング層を追加して、1つの層を、高さ×幅×奥行き(色など)の3次元で表し、 画像などの2次元の特徴を認識できるようにしています。
全結合層(これまでに説明してきたニューラルネットワークの層)では、1つの層を1次元で表していました。
そのため、画像などの2次元のデータを扱うには、データを1次元に変換する必要があり、そこで画像としての特徴が失われる問題点がありました。
そこで CNN では、畳み込み層とプーリング層を追加して、1つの層を、高さ×幅×奥行き(色など)の3次元で表し、 画像などの2次元の特徴を認識できるようにしています。
2. 動画
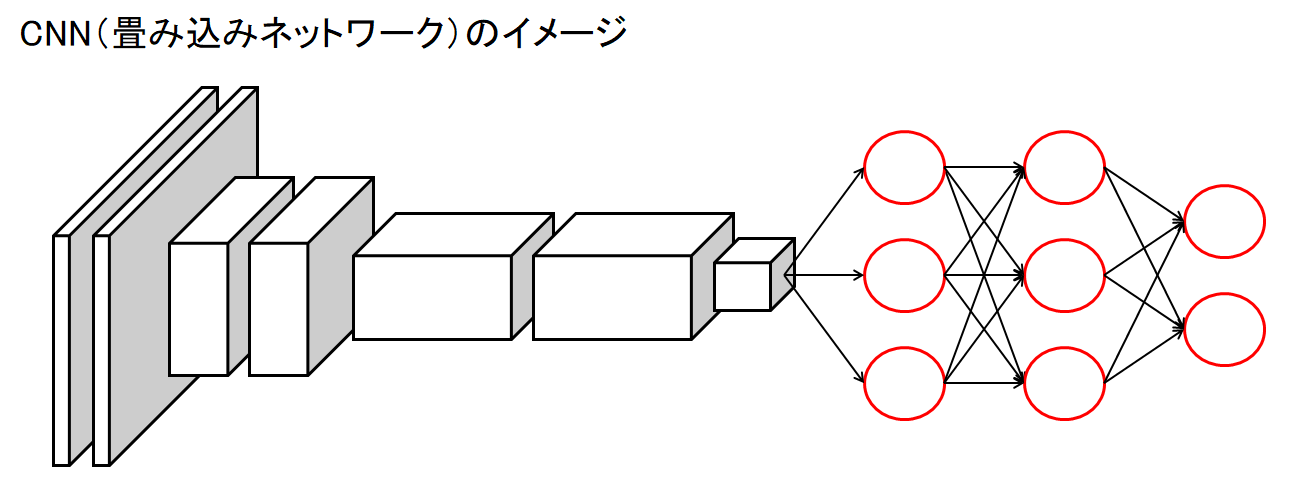
3. CNN の構成
CNN は、畳み込み層、プーリング層、全結合層などで構成します。
シンプルな CNN では、畳み込み層、プーリング層の順で並べて、これを何回か繰り返し、最後に全結合層を配置します。
全結合層では、今まで通り、ソフトマックス関数を使って分類を出力します。

参考:CNN の種類
EfficientNet、ResNeXt、ResNet、GoogLeNet、VGG、AlexNet、LeNet など。
シンプルな CNN では、畳み込み層、プーリング層の順で並べて、これを何回か繰り返し、最後に全結合層を配置します。
全結合層では、今まで通り、ソフトマックス関数を使って分類を出力します。
参考:CNN の種類
EfficientNet、ResNeXt、ResNet、GoogLeNet、VGG、AlexNet、LeNet など。
4. 畳み込み層
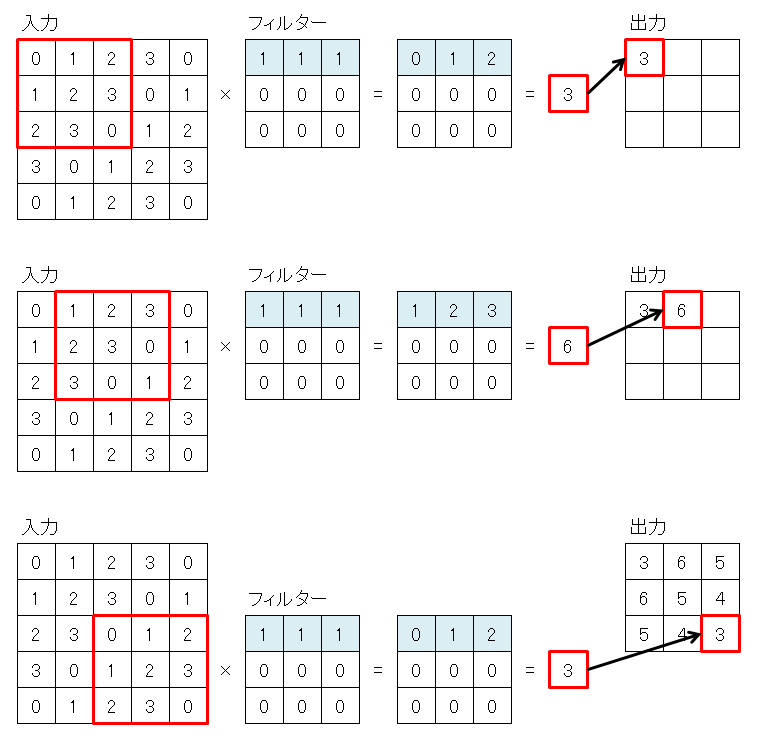
畳み込み層では、入力データの一部(フィルターと同じサイズ)とフィルター(重み)を乗算して合算します。
この時の乗算は行列の乗算ではなく、入力データにフィルターを重ねた時に、重なった値同士を乗算します。
1つ計算が終わったら、フィルターをずらして再度計算を行い、これを入力データの左上から右下まで行います。
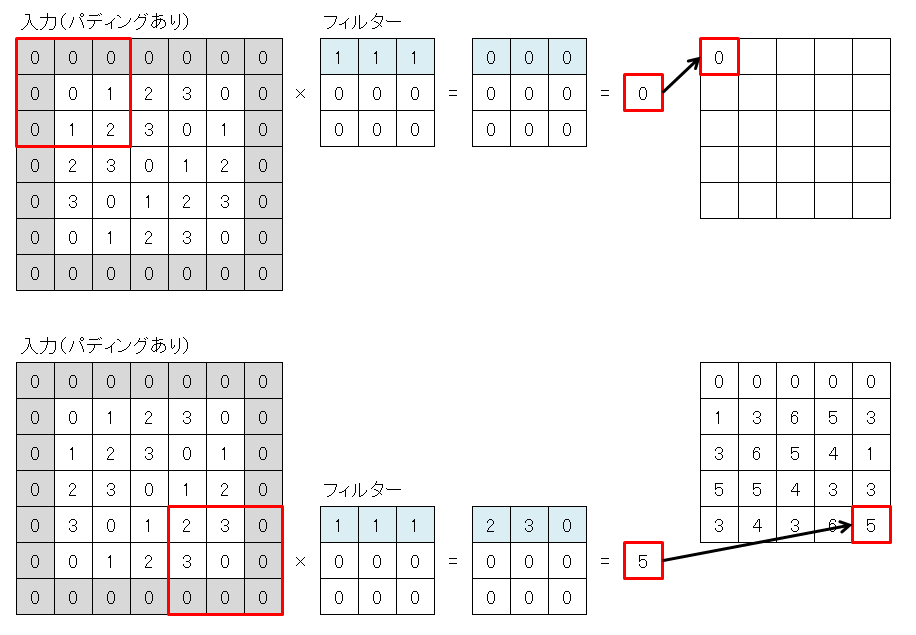
畳み込みを行うと、出力サイズが、入力サイズよりも小さくなります。
これは、入力データの周囲を0でパディングして、入力データを大きくすることで回避できます。
1つ計算が終わったら、フィルターをずらして再度計算を行い、これを入力データの左上から右下まで行います。
畳み込みを行うと、出力サイズが、入力サイズよりも小さくなります。
これは、入力データの周囲を0でパディングして、入力データを大きくすることで回避できます。
5. プーリング層
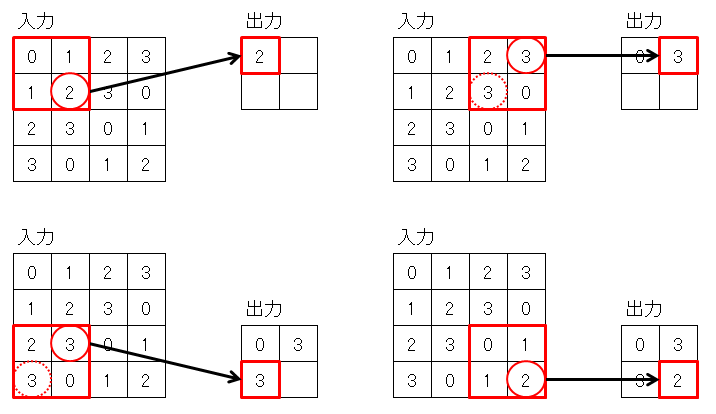
プーリング層では、入力データの縮小を行います。
入力データから 2×2 のデータを取り出して、その中の最大値だけを有効にすることで縮小します。
これを入力データの左上から右下まで行います。
この時、畳み込み層と異なり、一度縮小した範囲を重複しないようにずらす必要があります。
入力データから 2×2 のデータを取り出して、その中の最大値だけを有効にすることで縮小します。
これを入力データの左上から右下まで行います。
この時、畳み込み層と異なり、一度縮小した範囲を重複しないようにずらす必要があります。
6. CNN による図形判別
6.1 概要
CNN を使って、〇△□☆の4つの図形の判別を行います。
画像のサイズは 28×28 で、ペイントで適当に手書きで作成しました。
判別したい画像ファイルを test フォルダに4つ入れて実行すると、判別結果が出力されます。
画像のサイズは 28×28 で、ペイントで適当に手書きで作成しました。




判別したい画像ファイルを test フォルダに4つ入れて実行すると、判別結果が出力されます。
6.2 OpenCV のインストール
インストールされていない場合は、OpenCV をインストールします。
pip install opencv-python
6.3 フォルダ構成
c:\python\cnn
│
├─ hoshi ・・・ ☆ の学習用画像データ
│ ├─ 0.png
│ ├─ :
│ └─ 9.png
├─ maru ・・・ 〇 の学習用画像データ
│ ├─ 0.png
│ ├─ :
│ └─ 9.png
├─ sankaku ・・・ △ の学習用画像データ
│ ├─ 0.png
│ ├─ :
│ └─ 9.png
├─ shikaku ・・・ □ の学習用画像データ
│ ├─ 0.png
│ ├─ :
│ └─ 9.png
├─ test ・・・ テスト用画像データ
│ ├─ 0.png
│ ├─ :
│ └─ 3.png
│
└─ cnn.py(メイン)
6.4 学習用の画像ファイル
6.5 図形判別のソース
from keras.layers import Activation, Conv2D, Dense, Dropout, Flatten, MaxPooling2D
from keras.models import Sequential
from keras.utils import np_utils
import numpy as np
import cv2
# 学習データ
x = np.array([], np.int8) # 画像データ
y = np.array([], np.int8) # 正解データ
# 環境に合わせて変更してください。
dir_path = "c:/python/cnn/"
# 0 1 2 3
name_list = ['maru', 'sankaku', 'shikaku', 'hoshi'] # 〇 △ □ ☆
for kind, kind_name in enumerate(name_list):
for n in range(10):
# 画像データを読み込んで、学習データとして追加します
path = dir_path + kind_name + "/" + str(n) + ".png"
img = cv2.imread(path, cv2.IMREAD_GRAYSCALE) # グレースケールでファイル読み込み(縦 * 横 の2次元)
x = np.append(x, img) # 画像を1次元配列として追加
y = np.append(y, kind)
# 学習データを増やすため、画像を反転させたデータを学習データとして追加します
# 上下反転
img2 = cv2.flip(img, 0)
x = np.append(x, img2)
y = np.append(y, kind)
# 左右反転
img2 = cv2.flip(img, 1)
x = np.append(x, img2)
y = np.append(y, kind)
# 上下左右反転
img2 = cv2.flip(img, -1)
x = np.append(x, img2)
y = np.append(y, kind)
# 画像データを4次元に変換します
# print(x.shape) # (125440,) = 160 * 28 * 28 (160 = 10(画像数) * 4(種類) * 4(反転))
x = x.reshape(-1, 28, 28, 1)
# print(x.shape) # (160, 28, 28, 1)
# 正解を one-hot 表現に変換
# 0 -> [1 0 0 0]
# 1 -> [0 1 0 0]
# 2 -> [0 0 1 0]
# 3 -> [0 0 0 1]
y = np_utils.to_categorical(y)
# print(y)
# モデルの生成
model = Sequential()
# 畳み込み層
# 入力:(28 * 28, 1枚)
# フィルター:(3 * 3 * 1枚) * 32枚
model.add(Conv2D(filters = 32, kernel_size = (3, 3), strides = (1, 1), padding='same', input_shape = (28, 28, 1)))
model.add(Activation('relu'))
# 出力:(28 * 28, 32枚)
# 畳み込み層
model.add(Conv2D(filters = 32, kernel_size = (3, 3), strides = (1, 1), padding='same'))
model.add(Activation('relu'))
# 出力:(28 * 28, 32枚)
# 畳み込み層
model.add(Conv2D(filters = 32, kernel_size = (3, 3), strides = (1, 1), padding='same'))
model.add(Activation('relu'))
# 出力:(28 * 28, 32枚)
#----------------------------------------
# プーリング層
model.add(MaxPooling2D(pool_size = (2, 2))) # strides のデフォルトは pool_size
# 出力:(14 * 14, 32枚)
# 過学習の抑制(ランダムでニューロンの無効化)
model.add(Dropout(rate = 0.5)) # 50% 無効
#----------------------------------------
# 畳み込み層
# フィルター:(3 * 3 * 32枚) * 64枚
model.add(Conv2D(filters = 64, kernel_size = (3, 3), strides = (1, 1), padding='same'))
model.add(Activation('relu'))
# 出力:(14 * 14, 64枚)
# 畳み込み層
model.add(Conv2D(filters = 64, kernel_size = (3, 3), strides = (1, 1), padding='same'))
model.add(Activation('relu'))
# 出力:(14 * 14, 64枚)
# 畳み込み層
model.add(Conv2D(filters = 64, kernel_size = (3, 3), strides = (1, 1), padding='same'))
model.add(Activation('relu'))
# 出力:(14 * 14, 64枚)
#----------------------------------------
# プーリング層
model.add(MaxPooling2D(pool_size = (2, 2)))
# 出力:(7 * 7, 64枚)
# 過学習の抑制(ランダムでニューロンの無効化)
model.add(Dropout(rate = 0.5))
# 全結合層へ変換
model.add(Flatten())
# 出力:(3136)
# 全結合層
model.add(Dense(4096))
model.add(Activation('relu'))
# 過学習の抑制(ランダムでニューロンの無効化)
model.add(Dropout(rate = 0.5))
# 全結合層
model.add(Dense(4)) # 種類の数だけ用意する
model.add(Activation('softmax'))
# コンパイル
model.compile(
loss = 'categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'])
# 学習
model.fit(x, y, epochs = 30)
# model.load_weights('weights.hdf5') # 学習済みの重みデータの読み込み。読み込む場合は fit() 不要
# 重みの保存
model.save_weights('weights.hdf5')
# モデルの構造をテキスト出力
model.summary()
# テストデータ
test = np.array([], np.int8)
for n in range(4): # テストデータ4件
img = cv2.imread(dir_path + "test/" + str(n) + ".png", cv2.IMREAD_GRAYSCALE)
test = np.append(test, img)
test = test.reshape(-1, 28, 28, 1)
# 予測(分類)
result = np.argmax(model.predict(test), axis = 1)
print(result)
6.6 注意事項
以下のように acc が 0.25 から進まなくなる場合は、
pip list で tensorflow のバージョンが 2.x であることを確認してください。
私の環境ではなぜか 1.x になっており、仮想環境を新しく作り直したところ無事に動くようになりました。
pip list で tensorflow のバージョンが 2.x であることを確認してください。
私の環境ではなぜか 1.x になっており、仮想環境を新しく作り直したところ無事に動くようになりました。
Epoch 28/30
160/160 [==============================] - 3s 17ms/step - loss: 12.0886 - acc: 0.2500
Epoch 29/30
160/160 [==============================] - 3s 18ms/step - loss: 12.0886 - acc: 0.2500
Epoch 30/30
160/160 [==============================] - 2s 15ms/step - loss: 12.0886 - acc: 0.2500

