[Python]pipeline で文章の生成
公開日:2025-12-19
更新日:2025-12-19
更新日:2025-12-19
1. 概要
pipeline を使用して、文章を生成します。
2. パッケージのインストール
コマンド
pip install torch
pip install transformers
pip install bitsandbytes
pip install accelerate3. コード
コード
# モデルの保存先の設定
# デフォルトでは、ダウンロードしたモデルは、C:\Users\{ユーザ名}\.cache\huggingface\hub に保存される
# 環境変数の設定は、pipeline の import 前に行う必要がある
import os
os.environ['HF_HUB_CACHE'] = 'e:/python/cache'
import torch
from transformers import pipeline, BitsAndBytesConfig
# 4bit量子化設定
quantization_config = BitsAndBytesConfig(
load_in_4bit=True, # 4bitでロード
bnb_4bit_quant_type='nf4', # 高品質な量子化方式
bnb_4bit_use_double_quant=True, # 圧縮
bnb_4bit_compute_dtype=torch.float16, # 計算はfloat16
)
generator = pipeline(
'text-generation',
model='elyza/ELYZA-japanese-Llama-2-7b-fast-instruct', #model='elyza/ELYZA-japanese-Llama-2-7b-instruct',
dtype=torch.float16,
model_kwargs={'device_map': 'auto', # モデルをCPUとGPUに自動的に分散
'quantization_config': quantization_config
}
)
system_prompt = 'あなたは誠実で優秀な日本人のアシスタントです。'
user_message = 'すごく寒いのですが、どうすればよいですか?'
prompt = f'<s>[INST] <<SYS>>\n{system_prompt}\n<</SYS>>\n\n{user_message} [/INST]'
result = generator(prompt,
max_new_tokens=300, # 生成するトークンの最大数。トークンは LLM が処理する最小単位。1つの単語が複数トークンになる場合もある
do_sample=True, # True : 次に出力するトークンを選択する時にランダムの要素を追加する。毎回結果が変わる
# False : 確率の高いトークンを選択するため常に同じ結果になりやすい
temperature=0.7, # 出力のランダムさ。
# 0.1 ~ 0.5 : 単調
# 0.7 ~ 0.8 : バランスが良く自然
# 1 ~ : 創造的
top_p=0.9, # 次のトークンの候補を確率順に並べて、確率に加算していき、0.9になるまでを選択するトークンの対象とする。低確率のトークンは排除する。
repetition_penalty=1.1 # トークンを繰り返し使う際のペナルティ
# 1.0 : ペナルティなし。何度も繰り返し使う
# 1.1 ~ 1.2 : 少し繰り返しを抑える。自然
# 2.0 ~ : 強引に繰り返しを避けるため不自然になる
)
print('-----')
print(result[0]['generated_text'])実行すると、最初にモデルを読み込むため、かなり時間がかかります。そのため、単発で使う用途には不向きです。
読み込み後は速く生成できるため、繰り返し生成させたい場合は、プログラムを常駐させるなどの工夫が必要です。
4. Gradio で対話型AI にする
4.1 パッケージのインストール
コマンド
pip install gradio4.2 コード
コマンド
import os
os.environ['HF_HUB_CACHE'] = 'e:/python/cache'
import torch
from transformers import pipeline, BitsAndBytesConfig
# 4bit量子化設定
quantization_config = BitsAndBytesConfig(
load_in_4bit=True, # 4bitでロード
bnb_4bit_quant_type='nf4', # 高品質な量子化方式
bnb_4bit_use_double_quant=True, # 圧縮
bnb_4bit_compute_dtype=torch.float16, # 計算はfloat16
)
generator = pipeline(
'text-generation',
model='elyza/ELYZA-japanese-Llama-2-7b-fast-instruct', #model='elyza/ELYZA-japanese-Llama-2-7b-instruct',
dtype=torch.float16,
model_kwargs={'device_map': 'auto', # モデルをCPUとGPUに自動的に分散
'quantization_config': quantization_config
}
)
import gradio as gr
def chat_with_elyza(message, history):
prompt = f'<s>[INST] <<SYS>>\nあなたは誠実で優秀な日本人のアシスタントです。\n<</SYS>>\n\n{message} [/INST]'
result = generator(
prompt,
max_new_tokens=300,
do_sample=True,
temperature=0.7,
top_p=0.9,
repetition_penalty=1.1
)
response = result[0]['generated_text'][len(prompt):].strip()
return response
# チャットインターフェースの作成
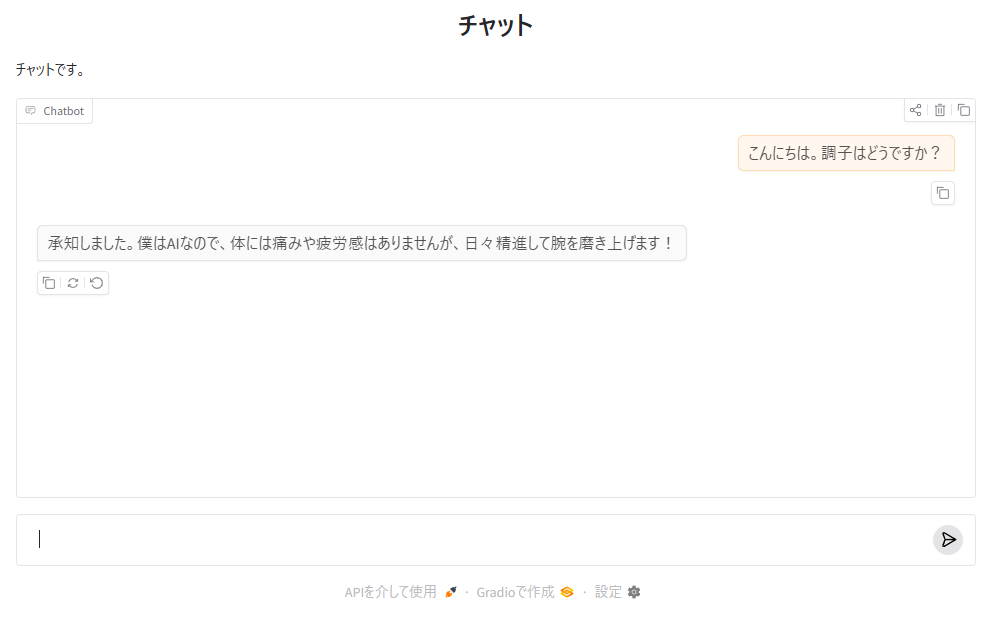
chat = gr.ChatInterface(
fn=chat_with_elyza,
title="チャット",
description='チャットです。'
)
# チャットの起動
chat.launch()実行後、ブラウザで http://127.0.0.1:7860/ にアクセスすると、対話型 AI として使えます。